News
|
February 4, 2026
Reduce compliance risk and speed FOIA with records born audit-ready
Public Sector
Back to All News

State and local governments are under pressure to adopt AI while meeting FOIA/open-records, retention, privacy, and audit requirements. Learn a practical “records first” approach: standardize, validate, secure, and make records traceable, so AI can be used safely and defensibly.
FOIA timelines are measured in days. Real-world processing is measured in weeks (sometimes months) because records aren’t consistently searchable, packaged, or traceable at the moment they’re created... because the records aren’t ready when the clock starts.
Government-wide, average processing time for simple requests rose to 44 days in FY2024 (up from 39.4 days in FY2023).
OGIS also notes simple processing time nearly doubled from 20.5 working days (FY2014) to 39.4 working days (FY2023).
And demand keeps rising. The federal government received a record 1,501,432 FOIA requests in FY2024 (+25.15% year over year).
A request comes in and your team has to assemble a defensible response across SharePoint sites, shared drives, email archives, line-of-business apps, and legacy ECM/RIM systems, often with inconsistent file formats, missing text layers, and incomplete metadata. Meanwhile, leadership is asking you to “use AI” to modernize operations, as long as safeguards and human oversight are built in.
Here is how Mickey Garcia (Head of Product Management, Adlib) and Mike Rattigan (ARMA International) framed it at the recent session on "Modernizing RIM for AI Era in State/Local Government": AI is only as defensible as the records you feed it, and modernizing RIM means building records that are “born audit-ready and AI-ready”.
In our webinar poll of state and local attendees, the top obstacles to scaling AI were operational and governance realities:

In other words: teams want AI outcomes, but they’re being held back by the “records reality” upstream.
That’s especially painful because public records timelines are not forgiving. At the federal level, FOIA requires agencies to determine how they will respond within 20 working days (subject to specific provisions and exceptions). In California, the Public Records Act requires agencies to determine within 10 days whether a request seeks disclosable public records, with an extension of up to 14 days under certain “unusual circumstances.”
And while state penalties vary, the risk isn’t theoretical. FOIA litigation can result in:
Even if your agency is not federal, federal records mandates are a strong indicator of where “good” is heading. OMB/NARA’s transition to electronic records management established clear deadlines, reinforced via updates (including M-23-07) that set June 30, 2024 as the date by which federal agencies must manage all permanent records electronically.
State and local governments feel the same directional pressure: modernize records operations, improve auditability, and reduce response risk, while making room for safe automation and AI.
That’s why the “records born audit-ready” idea matters. It turns modernization from an abstract strategy into an operational control point.
Adlib defines the Document Accuracy Layer as an upstream, automated control point that converts untrusted inputs (scans, emails, CAD, legacy formats, mixed PDFs) into trusted, compliant-ready, AI-ready records, with provenance, validation, and policy context embedded.
This is not “AI for AI’s sake.” It’s the mechanism that makes FOIA and compliance workflows faster without increasing risk, because it improves what you can prove about the records you produce.
Defensible AI Starts With the Document Accuracy Layer | eGuide
Stop paying the “trust tax” on AI. Learn how a Document Accuracy Layer makes content AI-ready (readable, validated, traceable, and audit-ready) with a practical AI-readiness checklist.
Download here
Records that are audit-ready (and safe to use downstream for search, summarization, and RAG) should meet these practical requirements:
The simplest way to explain Document Accuracy Layer to a state and local stakeholder is: it’s the “records readiness” layer between content sources and systems of record.
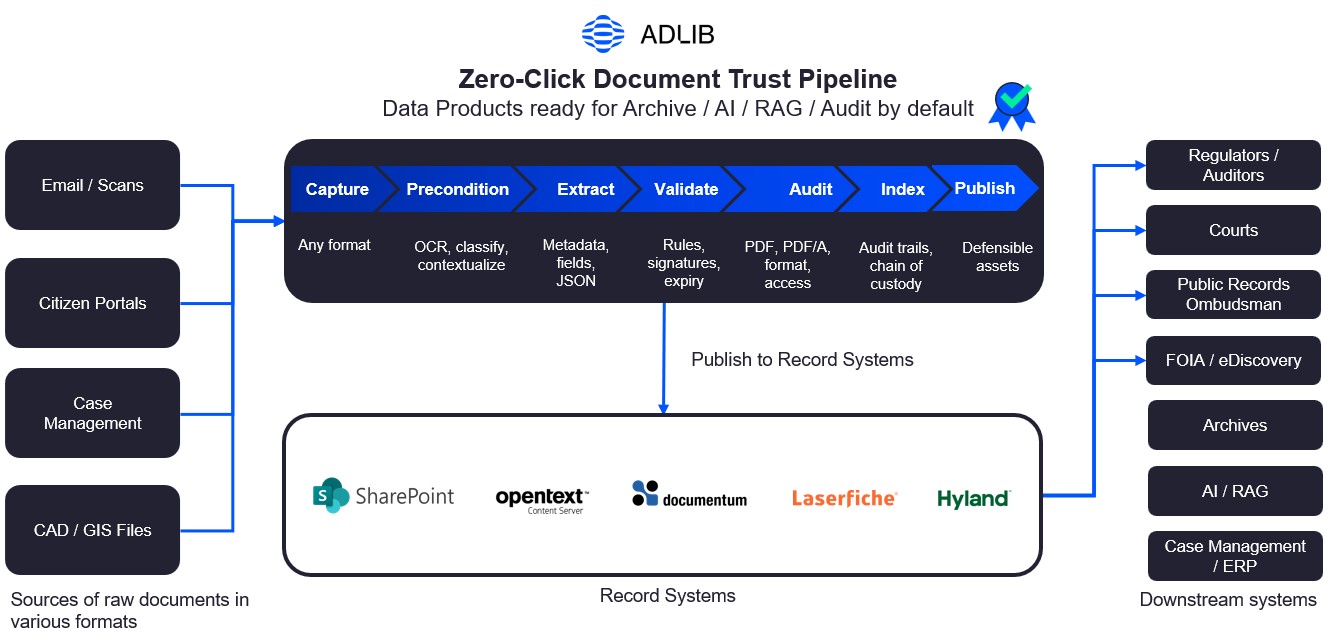
Adlib's Document Accuracy Layer connects to:
Adlib prepares and publishes into:
This is why Document Accuracy Layer is a pragmatic modernization move: it helps you modernize in place, without ripping out core platforms your agency relies on.
In the webinar poll, attendees overwhelmingly chose two “first” modernization bets: backfile conversion and FOIA response packages.

The biggest blockers to scaling AI (and improving compliance outcomes) are limited staff/time, trust/accuracy concerns, governance/metadata gaps, and too many file types. Backfiles and FOIA are where those four problems collide hardest and where automation pays back fastest.
Below is how to frame each use case through the lens of the Document Accuracy Layer.
Backfiles concentrate the hardest problems SLG teams called out:
In short: if you don’t modernize the archive, every downstream workflow (including FOIA) inherits that mess.
Think of it as an “archive factory line” that produces preservation-grade, searchable, policy-aligned records at scale.
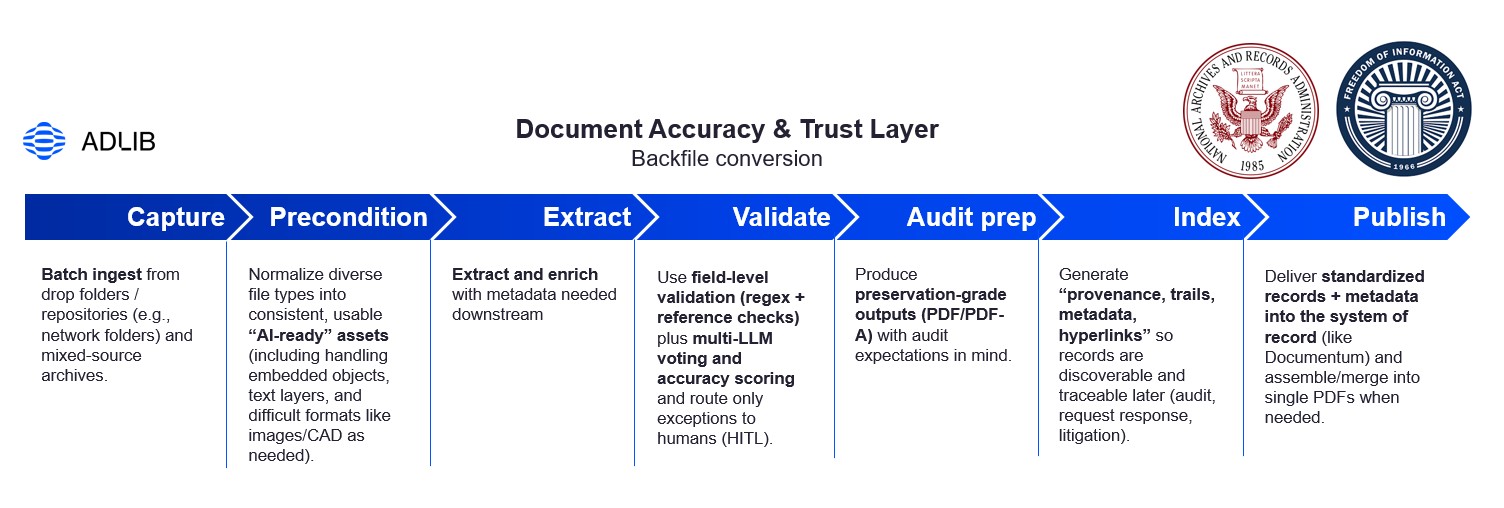
Rather than promising fixed ROI numbers, set measurable “acceptance criteria” and baseline improvements:
A strong first 60–90 days looks like: a repeatable pipeline, measurable throughput, a shrinking exception rate, and a clearly defined quality bar for “archive-ready.”
FOIA/PRA is where speed and defensibility collide. Capital project RIM modernization is “accelerating FOIA/FOIL response” and reducing manual prep by generating request-ready, consistently searchable packages, because inconsistent outputs + limited traceability increase compliance risk.

Benchmarks should map to speed + defensibility:
If this still feels abstract, the webinar examples make it concrete:
The pattern is consistent: when you reduce variance in records (formats, fidelity, metadata, provenance) and automate validation and packaging, your FOIA response speeds up while compliance risk goes down because you can prove what you produced, where it came from, and how it was processed.
That’s what “records born audit-ready” really means: fewer surprises, fewer exceptions, and a faster, more defensible response posture today, while laying the foundation for safe AI experiences tomorrow.
Want the full walkthrough of the Document Accuracy Layer in state & local government, including real-world FOIA and backfile examples? Watch the webinar recording here.

Take the next step with Adlib to streamline workflows, reduce risk, and scale with confidence.