News
|
March 13, 2026
Why Industrial AI Struggles to Scale: 6 Brownfield Challenges That Expose the Need for an Accuracy and Trust Layer
Energy
Manufacturing
Back to All News
.png)
Industrial AI depends on trusted data. Discover the brownfield document challenges slowing digital twins and why an accuracy and trust layer is emerging.
Industrial AI is hitting a predictable ceiling.
Pilot projects look promising. Executive teams see early value. But when organizations try to scale AI across real plants, mills, refineries, and energy facilities, progress slows down fast.
The usual explanations are familiar: budget constraints, change management, integration complexity, and competing priorities.
Those issues are real. But in most brownfield environments, they are not the true blocker.
The deeper issue is that industrial AI is only as reliable as the data foundation beneath it. And in many facilities, the operational truth still lives inside unstructured documents — engineering drawings, scanned P&IDs, maintenance records, redlines, manuals, and compliance files.
That creates a serious trust problem.
Because before digital twins, AI copilots, predictive maintenance, or industrial analytics can operate at scale, companies need a way to turn document-heavy operational reality into structured, validated, traceable data that the business can trust.
Different conversations, same pattern. The technology may be improving quickly, but the trust foundation underneath it is still too weak in many brownfield environments.
In other words, the challenge is not model intelligence. It is data integrity. If the document layer underneath an industrial environment is fragmented, outdated, or impossible to validate, every downstream AI system inherits that risk.
That matters because documents are not just supporting artifacts in industrial operations. In many cases, they are still the system of record. They contain the evidence, context, lineage, and change history that engineers, operators, auditors, and regulators rely on to make decisions.
And in brownfield environments, that work is still far from solved.
A lot of the market conversation around digital twins starts from an implicit assumption: the underlying engineering data is already structured, connected, and usable.
In greenfield environments, that assumption can hold.
If a facility was designed inside platforms such as AVEVA, Siemens COMOS, Bentley, or Dassault 3DEXPERIENCE, there is a much cleaner path from engineering system to twin. The design data was born digital. Relationships are more explicit. The model has a strong starting point.
But that is not how most industrial companies operate in the real world.
Most plants, mills, refineries, utilities, and process facilities are brownfield environments. They have grown, changed, and adapted over years or decades. Their records are fragmented. Their assets have drifted from original designs. Their documentation is spread across shared drives, ECM systems, engineering repositories, PDFs, scans, and contractor files.
So the challenge is not simply how to build a digital twin. It is how to build a trustworthy digital twin when the operational truth is trapped inside unstructured documents.
That is a very different problem.
A useful way to think about this is as an AI data supply chain problem. If the upstream document layer is inconsistent, incomplete, or unverified, then every downstream system, whether it is a digital twin, a copilot, a workflow engine, or an analytics model, starts from compromised inputs. And compromised inputs lead to untrusted outcomes.
In brownfield operations, critical knowledge tends to live in places machines struggle to use, like scanned P&IDs, legacy PDFs, redlined engineering drawings, vendor manuals, regulatory and compliance records… the list goes on.
To a human being, these documents are incredibly valuable. Engineers know how to read them. Operators rely on them. Auditors inspect them. Maintenance teams use them every day.
But to an AI system, they are often just opaque files.
That is where many industrial AI strategies start to wobble. Many leaders assume they have the data because they have the documents. But having documents is not the same as having AI-ready data. AI-ready data has to be structured, validated, traceable back to source, and usable across systems in a way engineers, operators, and compliance teams will trust.
And that gap is exactly where projects start to stall.
One of the most useful ways to understand the brownfield challenge is as a three-layer maturity model. The first layer is familiar. The second is where most projects bog down. The third determines whether the twin can actually be trusted by the business.
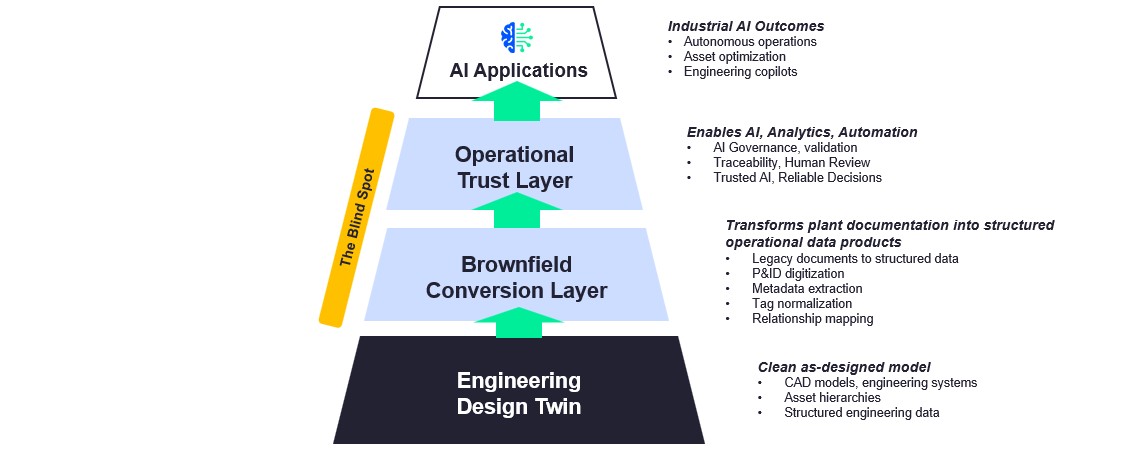
This is the layer most people think of first. It includes structured engineering data, models, asset hierarchies, and system relationships created inside engineering platforms.
This is where major vendors are strongest.
This is where the real pain starts.
It is the work of turning legacy, document-heavy, inconsistent information into usable structure. That sounds straightforward until teams try to do it in production. In practice, it means extracting metadata, interpreting diagrams, reconciling conflicting records, normalizing tags, preserving source lineage, and validating outputs before they feed operational systems. This is not a simple OCR exercise. It is an accuracy, context, and trust problem.
This layer gets much less attention than it should.
This is the layer that determines whether the twin can actually support the business. It is where governance, validation, provenance, traceability, and human review come together to make AI outputs explainable and defensible in real operating environments.
Because if teams do not trust the twin, they will not trust the AI systems built on top of it.
That is the wedge I think the market still underestimates.
The first layer is relatively mature. The second and third are where brownfield projects either gain traction or get stuck. Those two layers are also where the same operational problems tend to show up again and again.
When these foundational issues are ignored, brownfield AI programs tend to run into the same operational barriers again and again. The pattern is consistent across manufacturing, energy, and other asset-intensive industries.
In many facilities, the most important operational knowledge still sits inside documents, and those documents are often the official record.
That means companies cannot treat documents as a side issue when building digital twins or scaling industrial AI. In regulated, high-stakes environments, documents are the source of truth, the evidence trail, and the operational memory of the business.
This is one of the clearest examples of the brownfield problem.
People sometimes assume that once you can detect symbols or read a tag on a diagram, you have solved the issue. You have not.
Finding “P-101” on a drawing is easy. Determining how that pump connects to lines, valves, instruments, and process context in a way engineers will trust is something else entirely.
That requires more than OCR. It requires relationship mapping, context, and validation.
This is why P&ID digitization is still very much an open problem in practice.
What makes this especially important is that the business does not just need extracted content. It needs a representation of the process context that can stand up to engineering scrutiny. Without that, digitization may look impressive in a demo but fail in production.
Plants change. Constantly.
So even when a digital twin is built from structured engineering data, it may reflect the plant as it was designed, not as it is actually operating today.
Closing that gap is not just a modeling exercise. It requires a repeatable way to pull operational changes out of inspection reports, redlines, maintenance records, and engineering updates; reconcile them against existing asset data; and preserve a clear line back to the source material.
In other words, the problem is not simply creating a model of the plant. It is maintaining a trustworthy representation of the plant as it actually operates, with a verifiable link back to source evidence.
Most facilities do not live in one vendor ecosystem.
They operate across combinations of engineering tools, historians, asset management systems, ERP platforms, contractor repositories, and local document stores. One site might use AVEVA for part of the engineering stack, SAP for asset processes, a historian such as PI, and then a whole separate trail of files coming from EPCs and service vendors.
That is why interoperability remains such a stubborn issue.
The problem is not just moving files from one system to another. It is preserving meaning, context, and traceability across them so the resulting data can be trusted by both machines and humans.
Our customers tell us often that they do not need another rip-and-replace platform. They need a layer that can normalize complex documents, enrich and validate metadata, preserve lineage to source, and create audit-ready data products for downstream AI and operational systems.
In industrial environments, trust is earned.
Engineers, operators, and compliance teams are accountable for real-world outcomes. Safety, uptime, quality, and regulatory exposure are all on the line. So while automation can absolutely accelerate extraction and classification, it cannot be a black box.
What matters is not just whether a system produces an output. It is whether people can trust how that output was produced.
That means being able to answer questions like:
This is why the most effective industrial workflows tend to combine automated extraction, confidence scoring, exception handling, human validation, and traceability back to source.
Without that chain of validation and traceability, digital twins and industrial AI systems may look impressive, but they will struggle to support decisions that engineers and the business are willing to stand behind.
This is the part that slows many initiatives down.
A lot of brownfield projects still depend on manual cleanup, metadata reconciliation, workshop-based validation, and one-off services work to bridge gaps between legacy documents and structured systems.
That effort is often necessary. But it is also expensive, slow, and hard to scale across large portfolios.
Which is why so many organizations get through the pilot and then hit a wall.
The technology may be promising. The labor model behind it is not.
The reason this issue is becoming more urgent is simple: organizations are asking more of AI.
That requires more than model performance.
It requires trusted inputs and a repeatable industrial AI governance framework.
And in industrial settings, trusted inputs often begin with documents.
This is where I believe the market is heading.

Industrial companies do not just need more AI. They need infrastructure that closes the gap between engineering design systems and industrial AI applications.
In brownfield environments, that gap has two parts.
First, legacy plant documentation has to be converted into usable operational structure.
Second, that structure has to be validated, governed, and traceable enough for engineers and the business to trust it.
That is why the missing layer is much bigger than a conversion problem... it is an accuracy and trust problem.
Companies need a layer that can:
This is where an accuracy and trust layer becomes critical: spanning brownfield conversion and operational trust to turn messy, high-volume, multi-format content into validated, AI-ready data and compliant outputs.
That is the groundwork that makes larger AI ambitions more realistic.
When organizations close the gap between engineering data and trusted operational knowledge, several measurable outcomes improve.
At the operational level, the impact often shows up first in exception handling. In large industrial environments, reducing exception queues can return significant labor capacity to the business, shorten cycle times, and free engineers to focus on reliability, modernization, and higher-value decisions.
At the strategic level, the payoff is broader. Better validation and traceability can shorten cycle times, improve audit responsiveness, and make higher-value AI use cases more deployable because the underlying data is more trustworthy. That is the difference between using AI as a pilot program and using it as operating infrastructure.
If you are serious about scaling industrial AI in a brownfield environment, these actions should happen now.
Start with the document layer, not the model layer.
Where does critical engineering and operational knowledge live today? Which workflows still depend on manual document handling? Where do trust and validation break down?
Do not assume the digital twin platform alone will solve the legacy problem.
If the brownfield conversion layer is ignored, the twin may be technically impressive but operationally thin.
The organizations that move fastest are not the ones that automate recklessly. They are the ones that create a trusted path from document to data to decision.
That is what makes scale possible.
The industrial AI conversation often starts with models, applications, and automation.
In practice, success starts earlier.
It starts with whether the operational truth of the business can be transformed from fragmented, document-heavy evidence into structured, validated, traceable data that teams can trust.
That is the blind spot in many brownfield AI strategies.
And it is why the next phase of digital twin maturity will not be defined only by better models or better applications. It will be defined by better accuracy, better provenance, and better trust in the document layer underneath them.
For industrial leaders, the implication is clear: if you want trusted AI outcomes, you have to solve the document problem upstream.
Because in brownfield environments, trustworthy AI begins with trustworthy documents.
About the Author

Chris Huff is a growth-focused tech and SaaS executive with a proven track record in scaling enterprise software companies backed by private equity and venture capital. He’s known for building strong teams and driving value through operational efficiency, revenue growth, and product innovation. Prior to joining Adlib, Chris was CEO at Base64.ai and Chief Strategy & Growth Officer at Tungsten Automation (formerly Kofax), where he led strategy, product, AI, GTM, marketing, and partnerships. He also co-led Deloitte’s U.S. Public Sector Intelligent Automation practice and served as a Major in the U.S. Marine Corps. Chris brings deep expertise in AI, automation, and digital transformation, and a clear vision to expand Adlib’s impact across regulated industries.
Take the next step with Adlib to streamline workflows, reduce risk, and scale with confidence.