News
|
January 15, 2026
From CES 2026 to the Factory Floor: What “Physical AI” Means for Manufacturing Leaders
Manufacturing
Back to All News

Chris Huff’s CES 2026 takeaways for industrial leaders: physical AI raises the cost of bad inputs. Make documents clean, contextualized, and compliant.
CES 2026 reinforced a shift already underway: AI is moving from “insights” to action. AI is no longer confined to analytics dashboards and chat interfaces. It’s being embedded into workflows that touch equipment, quality, and production decisions. In industrial environments, that changes everything, because the cost of bad inputs doesn’t rise linearly. It spikes.
Here’s my lens: industrial operations still run on documents. They’re the system of record for compliance, safety, quality, engineering change, maintenance execution, and regulated approvals. And they’re often the least AI-ready asset in the enterprise: messy formats, inconsistent versions, missing metadata, scanned/image-heavy files, CAD complexity, and uncontrolled distribution.
If AI is going to operate in the physical world, it needs operational truth. In regulated industrial environments, that truth is documents and their data.
Industrial AI isn’t only about time-series data and sensor streams. Research on intelligent manufacturing explicitly calls out that modern analytics are designed to mine both structured and unstructured industrial data, and that continuous learning enables systems to become self-learning, self-optimizing, and self-regulating.
That’s the heart of the problem (and the opportunity):
Physical AI (industrial): AI systems that influence or execute real-world actions (maintenance decisions, quality holds, process changes, safety actions, autonomous machinery).
AI-ready documents: documents that are standardized, readable, validated, and enriched with context (metadata, version, provenance) so downstream analytics/AI can trust them.
Evidence-first pipeline: a pipeline where versions, transformations, validation rules, and exceptions are recorded so outputs are reproducible and auditable.
Document supply chain: treating documents like materials—intake → normalize → enrich → validate → govern → deliver.
If an LLM summarizes something incorrectly, you lose time.
If an autonomous or semi-autonomous system acts on incorrect instructions, you risk downtime, safety events, scrap, regulatory exposure, or warranty blowback.
IIoT World’s CES coverage of Siemens’ eXplore Tour makes the point in practical terms: seeing failure modes (and validating before execution) matters because industrial investments aren’t just expensive; they’re disruptive when they go wrong.
Chris Stevens (Siemens) put a sharper edge on the shift to simulation-first operations:
“It’s not something we want anymore, it’s something you have to do today. You have to virtually simulate your plant before you do anything: logistics, layout, the whole system. Then you take what you learn in the virtual world and apply it to the physical world.”
— Chris Stevens, Siemens (CES 2026)
My take on Chris’ statement: Simulation requires context, and much of that context lives in drawings, specs, procedures, revision history, and compliance records. If that documentation layer is wrong, incomplete, or inconsistent, you’re not simulating reality.

Industrial mini-scenario: In Siemens’ CES eXplore Tour demo (captured by IIoT World), a pick-and-place robot “fails,” triggering multiple alarms, then an AI assistant correlates live faults with historical data and engineering specs to diagnose the issue and get the line back online quickly. That’s directly relevant to “physical AI makes data defects operational defects”: when AI is guiding real-world actions, the quality and context of inputs (including specs, procedures, and revisions) determine whether you prevent downtime, or accelerate it.
Executive takeaway: As AI moves from advisory to execution, leaders will stop tolerating ambiguity in the documents that govern work, and as pipelines mature, they can target 10–20% less unplanned downtime or 20–30% faster cycle time in one document-heavy workflow over 12 months.
In process industries, researchers describe autonomy using a taxonomy of six autonomy levels, a structured way to define where you are today and what “more autonomous” actually means. They also point to why autonomy is pursued in the first place: business drivers include increasing yield, quality, and safety, while decreasing cost and energy consumption.

And the autonomy wave is real, but uneven. The Manufacturing Leadership Council notes that only 15% of manufacturers have transitioned to fully autonomous operations. That means most organizations are navigating partial autonomy and “dim” automation, where humans and machines share responsibility.
That middle ground is where input trust matters most. Partial autonomy often creates a false sense of security: you get automation benefits without the governance discipline needed to sustain it across sites, shifts, and product variants.
Executive takeaway: Treat autonomy as a staged program. Each step up the autonomy ladder requires tighter control over the documents that encode operational truth.
Industrial leaders are modernizing the “system layer” fast, especially MES and connected operations. But modernizing execution systems without addressing content quality just moves the bottleneck.
Info-Tech’s research on next-generation MES puts it bluntly: legacy MES systems lack the flexibility to scale and are becoming a barrier to embracing Industry 4.0, failing to keep pace with connectivity, real-time visibility, and advanced analytics.
That matters because MES isn’t just machine signals. It’s work instructions, quality attachments, deviation evidence, and the documents that explain why something happened, not just what happened.
Executive takeaway: If you’re modernizing MES and edge analytics, plan for the document layer as a first-class input, otherwise you’ll scale dashboards faster than you scale trust.
As manufacturers invest aggressively in AI, the Manufacturing Leadership Council reports 96% of manufacturers intend to increase AI investments over the next five years. Scaling is becoming the mandate.
But scaling changes the question. This next phase goes beyond “can we access the data?” and moves to:
This is the gap many teams feel but don’t name: AI-readiness is an evidence problem. You can’t govern what you can’t trace, and you can’t scale what you can’t defend.
Executive takeaway: Treat “AI readiness” as an evidence problem, not an access problem. Build pipelines that prove versioning, transformations, and fitness-for-purpose.
A useful simplification for industrial leaders:
And the higher the stakes, the more the business relies on the document trail.
When Siemens talks about bridging the real and digital worlds, Adlib’s focus is bridging AI to the operational documents that govern reality: procedures, specs, revisions, and compliance records.
Document readiness isn’t only a plant-floor story. It’s a supply chain story. It’s also a sustainability story.
A 2025 case-study paper on Intelligent Data Analytics in a U.S. electronics manufacturer reported tangible improvements after deploying analytics: 25% increase in forecast accuracy, 30% reduction in inventory, and 20% decrease in lead times. Meanwhile, a systematic review of 64 peer-reviewed articles highlights growing research interest in how big data analytics affects sustainable manufacturing supply chains across ecological, social, and economic dimensions.
The throughline is the same - analytics works when the pipeline is coherent. And in industrial reality, coherence often depends on unstructured artifacts that connect decisions end to end.
Executive takeaway: Better outcomes (inventory, lead times, sustainability) depend on upstream coherence, including the document evidence that makes operations defensible.
Most industrial teams are on a journey from “insights” to “action.” The fastest way to make that journey concrete is to use a simple ladder:
Where are you today: Level 1, 2, or 3? And where could you realistically be in 90 days for one workflow?
The goal of the next 90 days isn’t “AI everywhere.” It’s to move one high-risk workflow up the ladder, from standardized documents → validated data → provable evidence, so you can safely scale from insights to action.
Examples:
Tip: Choose a workflow with visible pain (rework, delays, audit findings) so you can measure ROI quickly. Set a pragmatic target like 10–20% lower unplanned downtime or 20–30% faster cycle time in the chosen workflow, then scale.
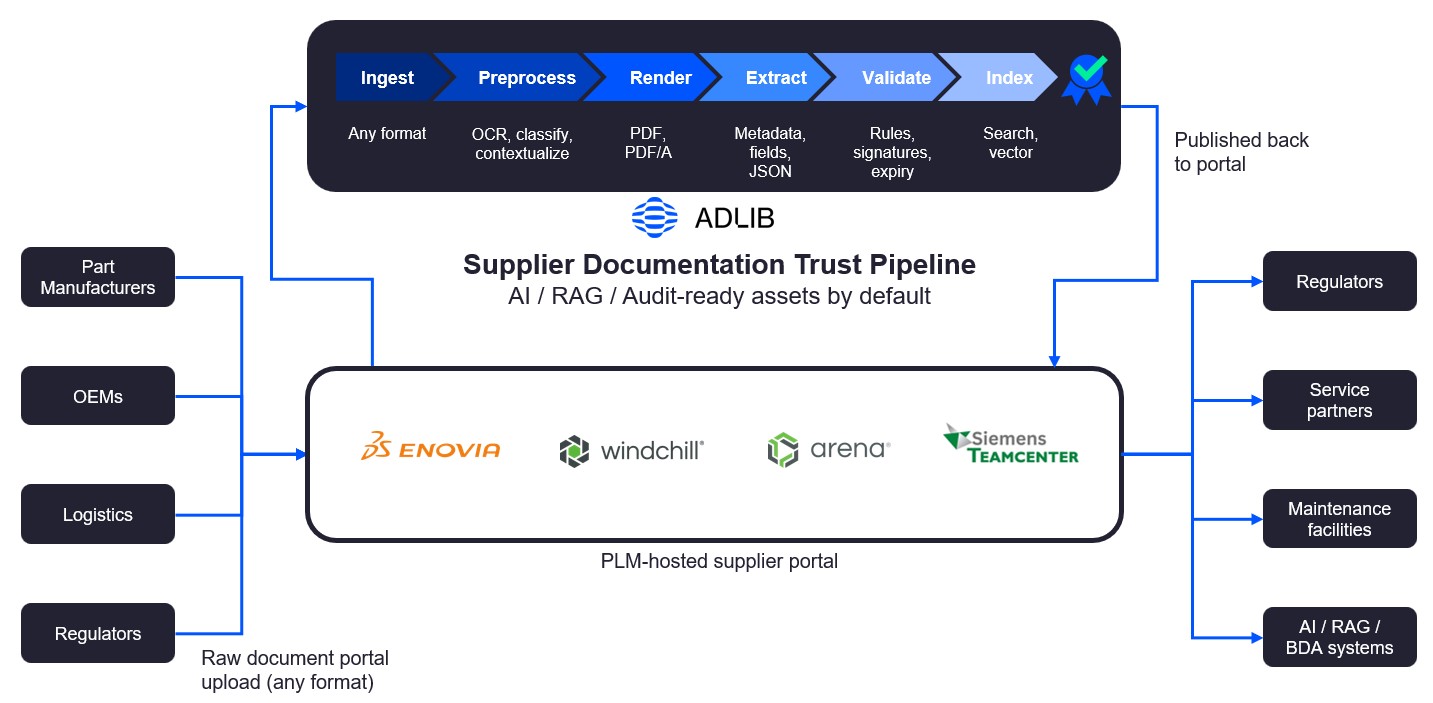
Here is an example of Adlib’s automated supplier documentation pipeline. This diagram shows the end-to-end supplier documentation flow: vendors submit content → Adlib normalizes, renders, extracts metadata, validates, and indexes → approved, shareable, audit-ready documentation is published to downstream systems and AI/RAG. Global aircraft and railcar manufacturers are reducing rework and risk by delivering validated, compliant, AI-ready documentation to PLM/QMS/MES, partners, and regulators.
"Sometimes we have drawing packages from the people building rail cars for us that are 300, 400, 500 drawings at a time... Adlib allows [our broad maintenance network] to see that information in PDF format, in a structured and a controlled way,"
- Supervisor of Technical Services, US National Rail Car Manufacturer
Minimum bar:
Practical acceptance criteria you can actually enforce:
Track:
Rule of thumb: if you can’t measure exception volume and causes, you can’t scale reliably.
AI that influences or executes real-world actions (maintenance, quality holds, process changes, safety actions, autonomous machinery) rather than only generating text or insights.
Because documents encode the operational truth: procedures, approvals, revisions, compliance evidence, and work instructions. If versions and context are wrong or missing, AI outputs aren’t defensible.
Documents that are standardized and readable, enriched with context (metadata/version/provenance), validated against rules, and governed so downstream systems can trust them.
CES 2026 put a spotlight on AI’s shift toward autonomy and physical execution. Manufacturing leaders are investing, but most organizations aren’t “fully autonomous” yet, and that’s exactly why inputs and evidence matter now.
If you want physical AI you can trust, start where industrial truth lives: documents. Make them clean, structured, contextualized, and compliant, so AI can operate effectively and defensibly in the real world.

About the author. Chris Huff is a growth-focused tech and SaaS executive with a proven track record in scaling enterprise software companies backed by private equity and venture capital. He’s known for building strong teams and driving value through operational efficiency, revenue growth, and product innovation. Prior to joining Adlib, Chris was CEO at Base64.ai and Chief Strategy & Growth Officer at Tungsten Automation (formerly Kofax), where he led strategy, product, AI, GTM, marketing, and partnerships. He also co-led Deloitte’s U.S. Public Sector Intelligent Automation practice and served as a Major in the U.S. Marine Corps. Chris brings deep expertise in AI, automation, and digital transformation, and a clear vision to expand Adlib’s impact across regulated industries.
Take the next step with Adlib to streamline workflows, reduce risk, and scale with confidence.
Audit one document-heavy workflow this quarter. Define “AI-ready + audit-ready” criteria, instrument exceptions, and build a repeatable document supply chain.