Document Accuracy Layer
A Document Accuracy Layer is the control layer that sits in front of Line of Business systems, LLMs, and RAG pipelines to make document-driven AI measurably accurate, traceable, and compliant, before downstream systems act on the results.
In regulated enterprises, accuracy can’t be an aspiration. It needs to be quantified, validated, and repeatable, especially when AI is involved.
Why a Document Accuracy Layer exists
Enterprises are under pressure to operationalize AI, but in regulated industries, AI is only as good as the content behind it. A Document Accuracy Layer helps teams reduce risk by ensuring AI operates on clean, validated, high-trust data.
It’s designed for environments where:
- source content is messy and multi-format (scans, PDFs, Office files, mixed-quality images),
- accuracy impacts compliance, audit outcomes, customer impact, or financial exposure, and
- teams need proof (not promises) that extracted data and AI answers are reliable.
What a Document Accuracy Layer does
A Document Accuracy Layer standardizes and validates documents so downstream AI can trust them. This “critical layer” ingests messy content and produces AI-ready outputs by:
- normalizing file types,
- applying fidelity-preserving rendering and advanced OCR,
- classifying and chunking content with citation anchors,
- enriching content with metadata,
- extracting information into structured data contracts, and
- validating outputs against the organization’s business and compliance rules.
Where it fits in the architecture
A Document Accuracy Layer sits between content sources and downstream AI/automation.
Upstream (sources): ECM, SharePoint, shared drives, email, line-of-business apps
Document Accuracy Layer: normalize → OCR/render → extract → validate → score trust → route exceptions
Downstream: IDP platforms, RAG pipelines, LLM applications, analytics, case management, workflow automation

How it works

Step 1: Ingest (control inputs + capture metadata)
Bring in raw documents from your systems of record (ECM/DMS, email/scan, PLM/QMS, RIM/EHS, vendor portals). The goal is to control what enters the pipeline and capture the metadata you’ll need later for governance, routing, and traceability.
Highlights for IT: connector/source controls, consistent job packaging, and metadata capture that downstream systems won’t strip.
Step 2: Precondition (OCR + classify + contextualize)
“OCR isn’t enough.” Preconditioning is about making documents machine-navigable while preserving structure and context, including scans, mixed layouts, tables, drawings, and revision artifacts.
Highlight for IT: structure preservation, layout/context handling, and pre-processing that reduces downstream variance.
Step 3: Extract (metadata, fields, JSON)
Extract the fields that drive decisions and package them into structured outputs (e.g., JSON), so downstream systems can reliably consume the results.
Highlight for IT: defined output “contracts” (fields + formats), consistent schemas, and field-level traceability hooks.
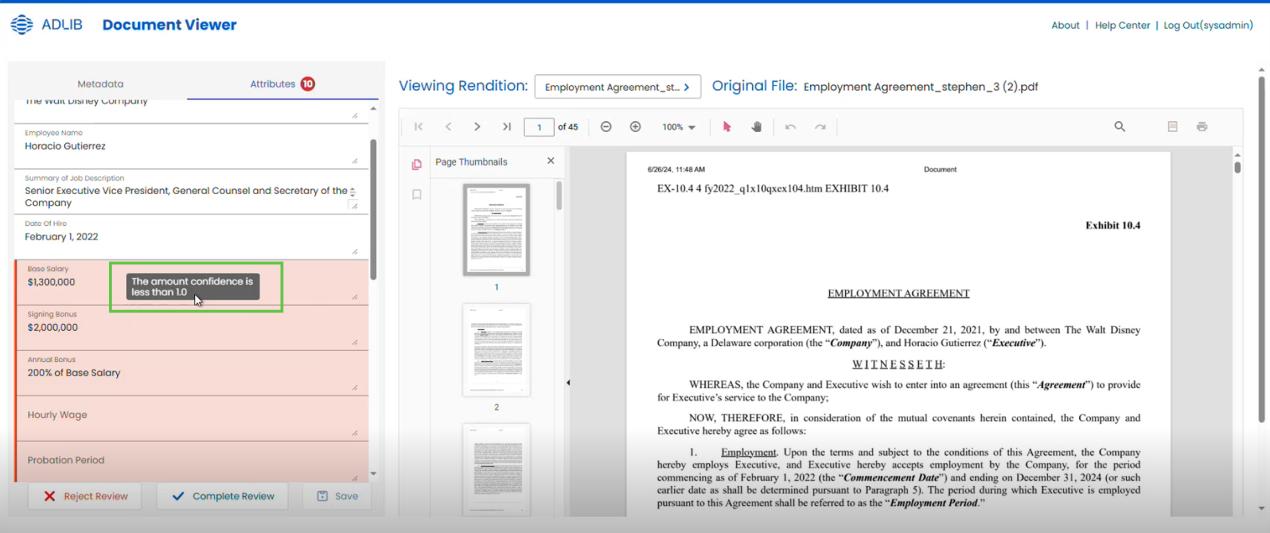
Step 4: Validate (rules + signatures + expiry + revision checks + confidence)
Validation is where “AI-ready” becomes trustworthy. Apply deterministic checks (rules, signatures, expiry, revision checks) and align validation outcomes to your risk thresholds so exceptions don’t silently ship.
Highlight for IT: validation gates, confidence thresholds, revision correctness, and policy-driven exception routing.
Step 5: Audit Prep (PDF/PDF-A, TOC, links, access)
Prepare defensible, audit-ready assets, preserving what matters for downstream review: document packaging, TOC, links, and access controls.
Highlight for IT: retention-ready packaging and evidence that survives handoffs.
Step 6: Index (search + vector retrieval that respects metadata)
Index for retrieval so copilots, RAG, and search experiences don’t ignore governance. Retrieval has to respect metadata and context, not just raw text.
Highlight for IT: metadata-aware retrieval (lexical + vector), chunking strategy aligned to traceability, and governance-friendly indexing.
Step 7: Deliver (defensible outputs to downstream systems)
Deliver AI-ready, audit-ready data products downstream (RIM/DMS, PLM/QMS, digital twin/robotics, vector DB/RAG stack, analytics/LLM workflows, regulators) without stripping traceability.
Highlight for IT: “don’t lose the chain of custody”, preserve metadata, provenance, and validation outcomes across integrations.
Self-test your pipeline
Use our 30-point AI-Readiness Checklist to pinpoint the gaps that create downstream AI risk.
What “accuracy” means in practice (for IT and architecture teams)
A Document Accuracy Layer operationalizes accuracy as signals + controls, not just model selection.
Core accuracy signals
- Model agreement: compare outputs from multiple LLMs to reduce variance and surface the most trustworthy result.
- Hybrid confidence scoring: blend probabilistic model confidence with deterministic validation checks.
- Document-level trust scoring (TrustScore): aggregate confidence across outputs to quantify document reliability.
- Evidence export: store confidence metadata (JSON/CSV) for audit, investigation, and governance.
Validation controls (typical patterns)
- Required-field checks (missing data fails validation)
- Format checks (date formats, identifiers, enums)
- Range checks (thresholds, numeric plausibility)
- Cross-field consistency (e.g., start date < end date)
- Policy/business rule checks (organization-specific)

How this supports RAG and “chat with documents”
RAG systems can produce “confident-sounding” answers from incomplete or poorly chunked content. A Document Accuracy Layer improves RAG reliability by ensuring documents are:
- normalized and readable,
- chunked with citation anchors (so answers can be referenced), and
- enriched with metadata for better retrieval.
Adlib describes an enhanced RAG “Chat with Documents” experience that delivers accurate, referenced answers sourced from the organization’s own documents.
FAQs
What’s the difference between a Document Accuracy Layer and IDP?
IDP focuses on digitizing and extracting information from documents. A Document Accuracy Layer goes further by adding measurable validation controls, like multi-LLM comparison, voting, hybrid confidence scoring, confidence metadata export, and document-level TrustScore, so outputs can be governed and audited.
How does multi-LLM voting improve accuracy?
LLM comparison and voting evaluates multiple model outputs to select the most reliable result, improving consistency and reducing manual validation.
What is hybrid confidence scoring?
Hybrid confidence scoring blends AI metrics with rule-based validation so accuracy can be evaluated using both probabilistic signals and deterministic checks.
What is TrustScore?
TrustScore is an aggregated, document-level confidence score combining results from all LLMs to provide an overall measure of output reliability.
When should we use human-in-the-loop validation?
Use HITL when your organization requires human oversight before finalizing extracted values. In Adlib, enabling HITL pauses processing and sends the job to a review queue until a human approves the extracted data.
Can we export confidence metadata for audit and governance?
Yes. Adlib supports exporting confidence metadata in JSON or CSV format for review or audit.