Life Science Regulatory Reporting Automation
Simplify your path to regulatory approval
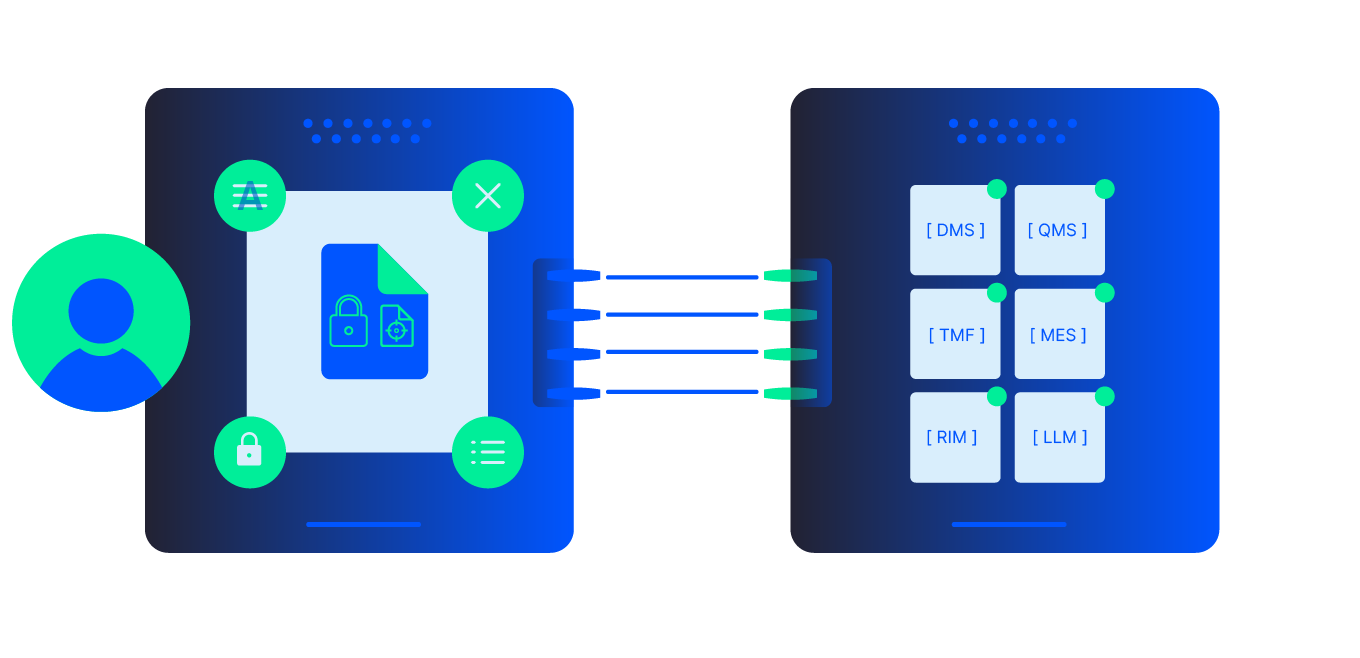
Adlib standardizes and merges large dossiers, runs automated PDF and formatting checks, and assembles submission-ready packages that integrate with RIM and QMS, helping you cut preparation time by ~50% and reduce rejection and rework risk.
Talk to Sales