AI Truth Gap: availability vs reliability vs actionability
In enterprise AI, the “truth gap” is the distance between:
- Availability: Can we access the information?
- Reliability: Can we trust it?
- Actionability: Can we use it to make a decision or trigger a process, confidently and fast?
Most AI programs stall because they over-invest in availability (more content indexed, more connectors, more models)… but under-invest in reliability (validation, provenance, auditability) and actionability (structured outputs, workflow routing, exception handling).
Why this matters (especially in regulated enterprises)
In regulated workflows, “close enough” isn’t close enough:
- If information is available but unreliable, you get hallucinations, incorrect extraction, or missing context, leading to rework, audit exposure, and slowed decision-making.
- If information is reliable but not actionable, it’s trapped in PDFs, scans, CAD, email attachments, and legacy formats, so teams can’t operationalize it across systems.
Accuracy & Trust Layer targets this “unstructured content bottleneck,” turning high-volume, messy documents into structured, validated pipelines for AI and downstream systems.
The 3-layer model: Availability → Reliability → Actionability
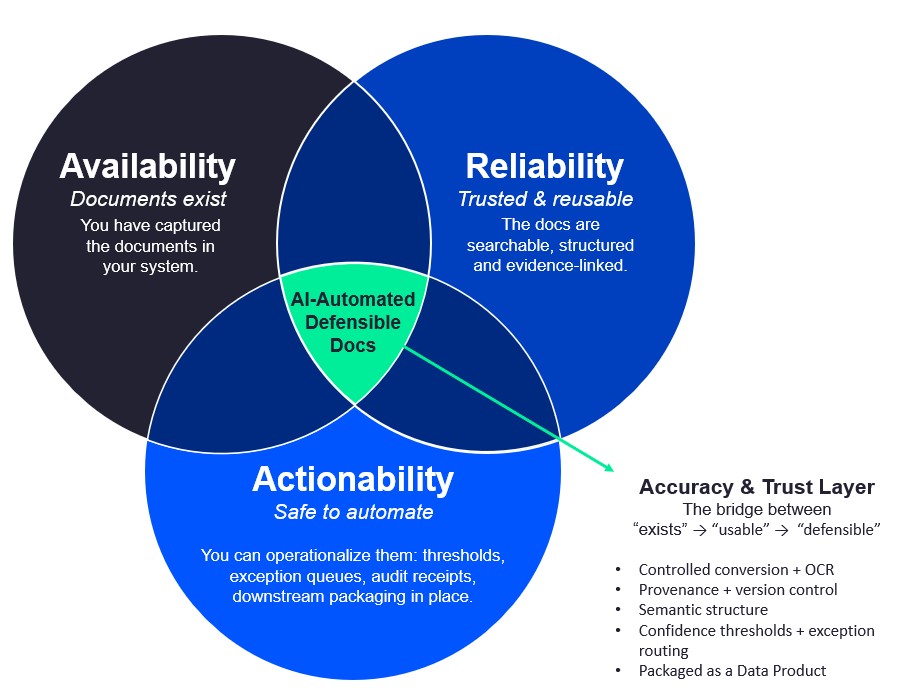
1) Availability (Access)
Goal: Make relevant content discoverable.
Typical tactics:
- Indexing content repositories
- Vector databases + embeddings
- RAG search / chat interfaces
Common failure mode: “We indexed it” becomes “we solved it,” but the AI still answers incorrectly because the underlying content is inconsistent, unreadable, or lacks the right structure.
2) Reliability (Trust)
Goal: Ensure outputs are provably accurate enough for the use case.
What reliability requires (in practice):
- High-fidelity rendering + OCR normalization (so the model is reading the right words)
- Validation signals (confidence, anomaly detection, cross-checks)
- Human-in-the-loop when confidence is low or risk is high
- Traceability: the “why” behind an answer, not just the answer
3) Actionability (Operational use)
Goal: Turn trusted information into decisions, workflows, and system updates.
Actionability means:
- Structured outputs (e.g., JSON “data contracts” for downstream systems)
- Automated routing (approve / reject / escalate / enrich)
- Exception handling that doesn’t create massive manual queues
- Integration into systems of record (ECM, QMS, CTMS, PLM, claims, etc.)
How the AI truth gap shows up in the real world
Example A: “We have the docs” (availability) but can’t trust the answer (reliability)
- The model can retrieve the policy document…
- But the scanned endorsement is skewed, missing fields, or partially unreadable…
- The answer is plausible, but wrong → claims leakage, compliance risk, rework.
Example B: “We trust the answer” (reliability) but can’t do anything with it (actionability)
- A reviewer confirms extracted values…
- But outputs aren’t mapped into the case system / RIM / QMS…
- Humans still copy/paste → cycle time stays slow.
Closing the gap with Adlib’s Accuracy & Trust Layer
Adlib is the “critical layer in front of LLMs and RAG pipelines,” transforming messy content into “AI-ready, machine-navigable pipelines” and validating outputs against business/compliance rules.
Here’s how that maps directly to availability vs reliability vs actionability:
A) Improve Availability without “garbage-in retrieval”
Adlib can:
- Normalize multi-format inputs and make them machine-navigable for pipelines
- Chunk content with citation anchors and enrich with metadata (so retrieval isn’t just “top-k similarity,” but grounded and explainable)
- Export encodings/embeddings for use in the customer’s vector database (so teams can keep their preferred RAG stack)
Result: Better recall + better grounding, because the underlying content is consistent and structured for retrieval.
B) Make Reliability measurable
Adlib Transform introduces:
- Accuracy Score (quantifiable trust score) combining:
- Multi-LLM voting
- Hybrid confidence scoring
- Layered validation signals
- LLM compare + confidence scoring + voting mechanisms to select the most trustworthy extracted data and reduce manual validation load
Result: Teams can define what “truthy enough” means (per workflow), then enforce it consistently.
C) Turn Reliability into Actionability (automation that knows when to stop)
Adlib brings:
- Confidence thresholds that trigger user-friendly human-in-the-loop review for exceptions (instead of blanket manual review)
- HITL review flows where reviewers can see extracted fields, highlight source text in the PDF, edit values, and complete/reject review, so exceptions become manageable work, not chaos
Then, Adlib connects trust to automation:
- n8n orchestration can trigger routing/correction/enrichment based on trust signals, explicitly linking accuracy → workflow execution
Result: The system doesn’t just “answer questions.” It produces validated outputs that can drive downstream decisions and processes.
Practical checklist: diagnosing your truth gap
If you’re stuck at Availability
- Your AI can “find documents,” but answers are inconsistent
- Same question returns different answers each time
- You can’t explain where an answer came from
If you’re stuck at Reliability
- You don’t have a quantifiable confidence/trust measure
- You rely on broad manual review because you can’t route exceptions intelligently
- You can’t pass an audit on how outputs were produced
If you’re stuck at Actionability
- Outputs aren’t structured for downstream systems (JSON/data contracts)
- No workflow routing based on confidence/validation outcomes
- Exceptions create queues that scale linearly with volume
Adlib’s Accuracy & Trust Layer is designed to move you across all three: normalize content → score trust → validate outputs → route exceptions → deliver structured, system-ready results.
FAQ
What is the “AI truth gap”?
It’s the gap between having information accessible (availability) and being able to trust (reliability) and use (actionability) that information in real workflows.
Why does the truth gap get worse with GenAI?
GenAI can produce fluent answers even when inputs are noisy, incomplete, or inconsistent, making reliability failures harder to detect and more expensive.
How do you measure reliability?
With confidence scoring + validation signals + exception handling. Adlib’s Transform introduces an Accuracy Score that combines multi-LLM voting, hybrid confidence scoring, and layered validation signals.
How do you make reliable AI outputs actionable?
By producing structured outputs, enforcing business/compliance validation, and using workflow automation (e.g., routing via n8n) to operationalize decisions.