News
|
March 27, 2026
OCR vs AI Document Processing: Why You Still Need a Trust Layer
All Industries
Back to All News

Compare OCR vs AI document processing and learn why preprocessing, validation, and trust layers are essential for accurate, AI-ready data in modern workflows.
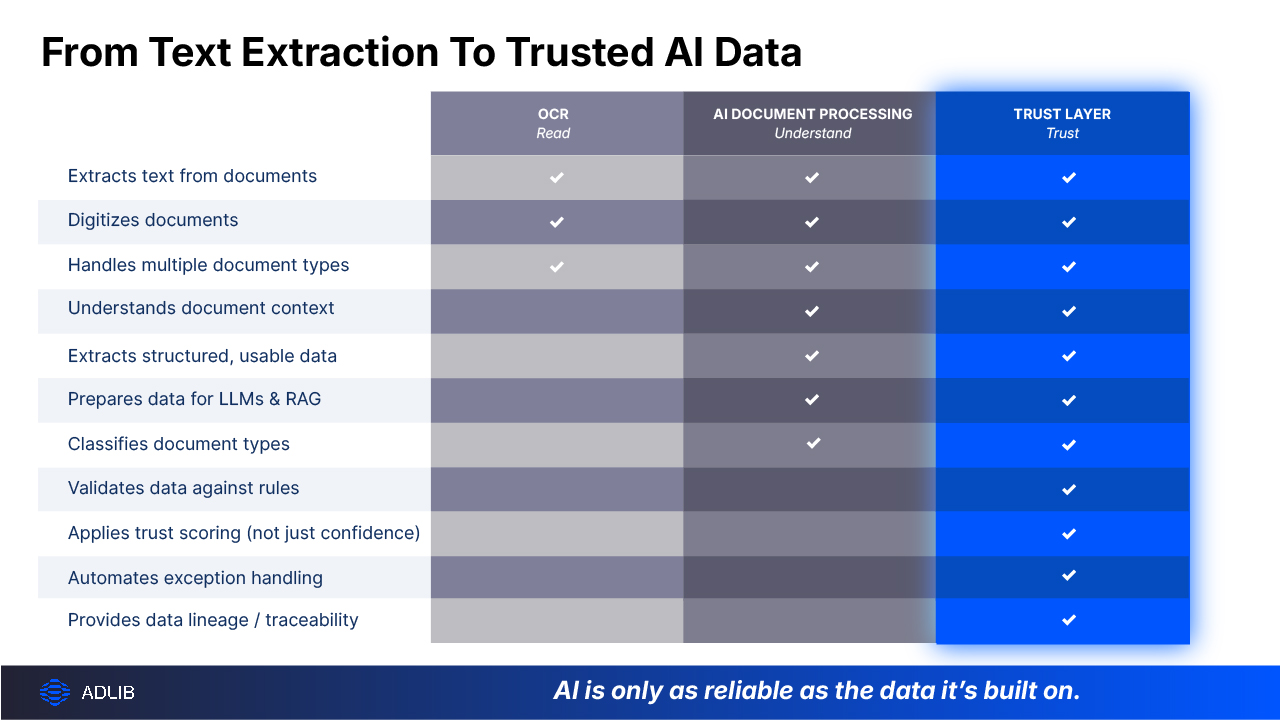
OCR turns documents into text. AI document processing turns documents into usable, structured data.
But in today’s AI-driven workflows (like LLMs, copilots, and retrieval-augmented generation (RAG) pipelines) that still isn’t enough. What really matters now is this: Can you trust the data those systems are using?
Because if you can’t, everything downstream, like automation, analytics, even AI decisions, starts to wobble.
This article breaks down the difference between OCR and AI document processing, where each fits, and why modern enterprises are adding a new layer entirely: a document trust layer that ensures data is validated, traceable, and truly AI-ready.
At a high level, the difference is simple.
A helpful way to think about it:
But if you’re feeding that brain messy, inconsistent, or unverified inputs… you still don’t get reliable outcomes.
That’s where things start to break down in real-world enterprise workflows.
OCR (optical character recognition) has been around for decades. It’s a mature and reliable technology, when the inputs are clean, consistent, and well-structured.
It follows a fairly straightforward process:
That’s it.
And to be fair, it works well for:
But the moment things get messy (like multiple formats, handwriting, tables, low-quality scans, which are very common in insurance claims or clinical trials) OCR starts to struggle.
And more importantly… It has no idea what any of that text actually means.
Here's the reality most enterprises face: 80–90% of business content is unstructured. Claims arrive in dozens of formats. Clinical trial documents contain handwritten forms and notes. Engineering documents mix text with diagrams. Lab notebooks combine typed entries with handwritten notes.
Traditional OCR wasn't built for this variability. It requires consistent templates and predictable layouts. When documents deviate, and they always do, OCR produces errors that cascade downstream, with initial character errors multiplying into 15–20% information extraction errors through post-processing steps.
So what happens? Teams spend hours manually reviewing OCR output, correcting mistakes, and reformatting data before it can feed into business systems or AI models.
This is why many organizations find that OCR alone cannot support modern AI initiatives. While it digitizes content, it does not make that content AI-ready, validated, or reliable enough for automation and decision-making.
Modern document workflows require more than text extraction. They require:
AI document processing platforms address these gaps by combining OCR with machine learning, natural language processing, and computer vision.
AI document processing uses artificial intelligence to extract, classify, validate, and structure document content automatically.
Unlike traditional OCR, AI document processing understands context. It recognizes that "123 Main Street" is an address, not just a string of characters. It distinguishes a vendor name from a total amount. It identifies document types without being told what to look for.
AI-based OCR (sometimes called intelligent OCR) is a component within broader AI document processing. It combines text extraction with neural networks that improve accuracy on complex documents that contain handwriting, degraded scans, unusual layouts, where traditional OCR fails.
The key difference is traditional OCR outputs flat text, while AI document processing outputs structured, validated data ready for downstream systems.
Because downstream systems, whether it’s an ERP, a claims platform, or an AI model, don’t want text.
They want clean fields, consistent structure, and reliable inputs. Without that, everything slows down or breaks.
This is where a lot of organizations get surprised. Even with AI document processing in place, they still see:
Why?
Because AI, no matter how advanced, is still working on imperfect, unvalidated inputs.
Before documents ever reach AI or Agentic systems, they need to be standardized, cleaned, structured, and most importantly, verified.
Think of it like preparing ingredients before cooking.
If you skip that step, it doesn’t matter how good the recipe (or the model) is.
This step is often referred to as document preprocessing for AI, and it plays a critical role in improving downstream model accuracy and reducing hallucinations.
A proper preprocessing layer:
This ensures the document is machine-readable in a meaningful way, not just technically readable.
Large language models don’t “understand” documents the way humans do. They rely entirely on the structure of the data, the quality of extracted content, and the context they’re given. If your documents are inconsistent, poorly extracted, and missing structure, then your AI outputs will be too.
This is where you start seeing hallucinations, incorrect answers, compliance risks.... In many cases, the issue is not the model at all, but the input. Poor document quality leads directly to poor AI outcomes.
This is where a new concept is emerging in enterprise AI architectures: the document trust layer.
It sits between document ingestion and downstream systems (including AI). Its job is simple, but critical: Make sure the data is actually trustworthy before anything uses it.
In modern architectures, this is often referred to as a document accuracy layer or trust layer, positioned upstream of core systems, LLMs, and RAG pipelines to ensure only validated, high-quality data flows downstream.
A trust layer goes beyond extraction. It ensures that every document is:
Instead of blindly passing data downstream, it acts as a gatekeeper.
Most systems today rely on confidence scores. But confidence alone isn’t enough. A model might be “90% confident”… and still be wrong.
Unlike basic confidence scores, trust scoring introduces measurable, policy-aware validation that determines whether data is safe to use in automation or AI-driven decisions. Trust scoring combines multiple signals:
The result is a more realistic measure of whether data can be trusted.
With trust scoring, you can automatically route low-confidence outputs for review or let high-confidence data flow straight through. This helps reduce manual work without increasing risk in regulated environments where decisions must be defensible.
It’s the difference between “this looks right” and “we can prove this is right”.
Today’s most effective document workflows aren’t just OCR + AI.
They’re layered.
Each layer builds on the last. Skip one, and problems show up later.
This layered approach reflects how enterprise AI document pipelines are evolving to support automation, analytics, and agentic workflows.
To be clear, OCR isn’t obsolete. It’s still useful for simple digitization, clean, structured documents, and low-risk use cases.
It’s just no longer sufficient on its own.
You’ll need more advanced approaches when:
Which, for most enterprises… is most of the time.
What’s changing isn’t just the technology. But the expectation. Organizations no longer just want digitized documents or extracted data. They want AI-ready inputs, validated outputs, and traceable decisions.
Because documents aren’t just files anymore.
In regulated industries, documents are not simply records, they are evidence. They must be accurate, complete, and defensible in audits and regulatory reviews.
As volume, variety, and compliance requirements increase, the case for AI document processing and trust layer strengthens. A 2025 SER survey found 65% of organizations are accelerating AI-driven IDP projects.
Organizations subject to FDA, SOX, SEC, or NRC requirements, alongside new 2026 AI compliance obligations like the EU AI Act and Colorado AI Act, want governed, traceable document workflows that traditional OCR cannot provide.
Regulated industries, life sciences, financial services, energy, government, face unique demands. Documents feeding AI models or business decisions require audit trails, validation workflows, data lineage, and compliance with industry standards.
AI document processing platforms built for regulated environments include these capabilities by design. They produce outputs that satisfy auditors, not just business users.
Building AI-ready document pipelines in compliance-heavy environments requires careful platform selection. The goal is accuracy, governance, and flexibility, without disrupting existing systems.
Use this checklist to self-assess the AI-readiness of your most complex workflows >
Traditional OCR is not AI, it uses pattern matching and rule-based algorithms, not machine learning. However, modern "AI-based OCR" or "intelligent OCR" incorporates neural networks and machine learning, blurring the line between the two technologies.
AI-based OCR combines text extraction with machine learning to handle variability, improve over time, and deliver higher accuracy on complex documents. Traditional OCR relies on static templates and struggles with anything outside its predefined rules.
Migration timelines vary based on document complexity and integration requirements. Platforms with pre-built connectors and industry-specific configurations can significantly accelerate deployment, often weeks rather than months.
Yes, enterprise-grade platforms support validation workflows, audit trails, human-in-the-loop review, and compliant output formats like PDF/A. These capabilities are essential for regulated industries where accuracy and traceability are non-negotiable.
Leading platforms support hundreds of file types including PDFs, scanned images, Microsoft Office documents, CAD files, and legacy formats. This breadth enables seamless ingestion into AI and analytics systems without format-specific workarounds.
Choose platforms that support multiple LLM providers and integrate with existing systems without requiring infrastructure changes. This flexibility allows organizations to switch models or vendors as requirements evolve, protecting long-term investments.
A document trust layer is an upstream validation layer that ensures documents are accurate, complete, and audit-ready before they are used by AI systems or business workflows. It combines preprocessing, extraction, validation, and trust scoring to produce reliable, AI-ready data.
LLMs fail when documents are poorly structured, inconsistently formatted, or incorrectly extracted. Without preprocessing and validation, the model receives low-quality inputs, leading to hallucinations, incorrect outputs, and unreliable decisions.
Take the next step to streamline workflows, reduce risk, and scale with confidence.
Schedule an AI-Readiness Workshop >
Take the next step with Adlib to streamline workflows, reduce risk, and scale with confidence.