AI-ready Architecture for Insurance
What does AI-ready architecture actually mean for insurance? This glossary defines the key terms, components, and concepts — including the Document Accuracy Layer that makes AI outputs trustworthy and defensible.
AI-ready architecture for insurance is the technical and operational foundation that enables AI systems, including large language models, intelligent document processing (IDP) tools, retrieval-augmented generation (RAG) pipelines, and automation platforms, to produce accurate, trustworthy, and audit-defensible outcomes in insurance workflows.
In insurance, AI-ready architecture is only as strong as the document layer that feeds it. Insurance operations run on documents: policy applications, claims submissions, loss runs, endorsements, certificates of insurance, adjuster reports, legal correspondence, and more. When those documents are unstructured, inconsistently formatted, unvalidated, or untraceable, every downstream AI system that depends on them inherits those flaws, producing unreliable extractions, undefendable decisions, and exception queues that grow rather than shrink.
A complete AI-ready architecture for insurance doesn't start with the AI model. It starts with document accuracy.
Why AI-Ready Architecture Matters in Insurance
Insurance is one of the most document-intensive industries in the world, and one of the most regulated. AI investments are accelerating across the sector: automated underwriting, straight-through claims processing, fraud detection, regulatory reporting, and customer service automation all depend on AI systems that can read, interpret, and act on document content reliably.
But the gap between AI ambition and AI performance in insurance is often not a model problem. It's a document problem.
Consider what feeds most insurance AI systems: scanned PDFs that weren't OCR'd correctly, loss runs exported from legacy systems with inconsistent formatting, claims forms where critical fields are in different positions across carriers, endorsements that reference prior policy versions without traceable linkage, and medical records submitted as flat image files with no machine-readable structure.
Feed those documents into an IDP system without validation. Feed them into a RAG pipeline as-is. The model will do its best, and its best will not be good enough for a regulated workflow where decisions must be defensible, auditable, and accurate.
AI-ready architecture for insurance solves this at the source. It establishes a Document Accuracy Layer that ingests raw, multi-format content; normalizes, validates, and enriches it; and produces clean, structured, traceable outputs that downstream AI systems can actually use, and that compliance teams can actually defend.
The Core Components of AI-Ready Architecture for Insurance
A complete AI-ready architecture for insurance includes the following layers:
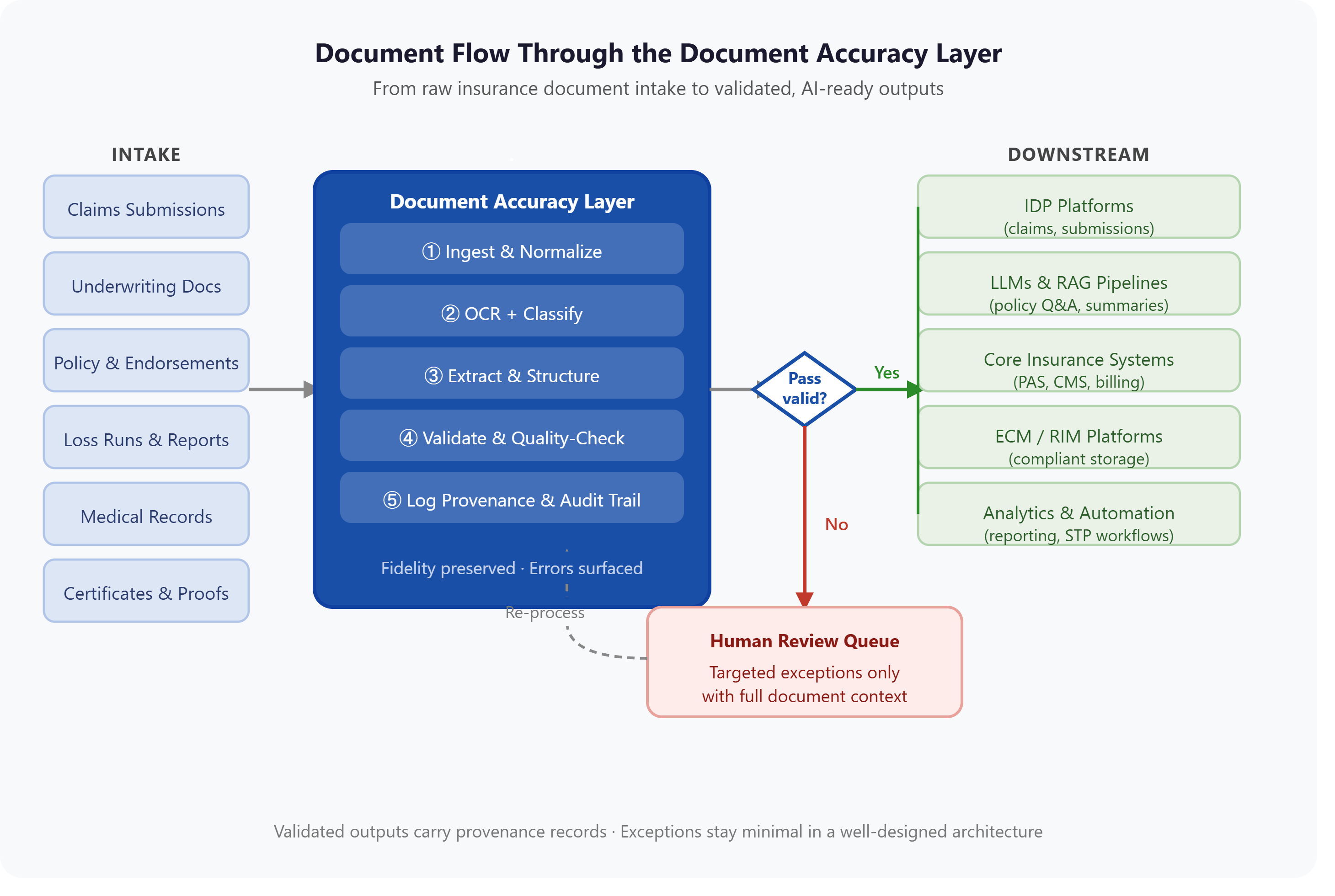
1. Multi-Format Ingestion
The entry point for all documents, such as PDFs, scanned images, Word documents, emails, faxes, legacy system exports, spreadsheets, and XML/EDI feeds. This layer must handle the full diversity of formats that actually exist in insurance operations, not just the formats that are convenient to process.
2. Document Normalization and Fidelity Preservation
Raw documents are converted into consistent, machine-navigable formats without losing the fidelity of the original, like layout, structure, tables, handwriting, stamps, and annotations included. Fidelity preservation matters in insurance because documents serve as legal evidence: what the original document said, and how it was structured, may be challenged in a claim dispute, audit, or regulatory review.
3. OCR and Content Extraction
Optical character recognition (OCR) converts image-based content into machine-readable text. In insurance, OCR accuracy is especially important for handwritten forms, aged documents, multi-column layouts, and carrier-specific form designs that don't follow standard templates. Poor OCR at this layer cascades into extraction errors, misclassifications, and downstream AI failures.
4. Document Classification
Documents are automatically identified and categorized by type, including claims form, policy declaration, medical record, loss run, legal notice, and so on. Accurate classification is prerequisite to accurate extraction: a model that doesn't know it's reading a certificate of insurance will not know where to look for the fields that matter.
5. Data Extraction and Structuring
Key fields, values, entities, and relationships are extracted from documents and structured into formats that downstream systems can consume, such as JSON, XML, structured database records, or API-ready outputs. In insurance this includes policy numbers, coverage limits, effective dates, claimant identifiers, loss amounts, reserve figures, and hundreds of other structured data points depending on the workflow.
6. Validation and Quality Checks
Extracted data is validated against rules, schemas, reference data, and cross-document logic before it advances downstream. This is the layer that catches OCR errors, misclassifications, missing required fields, out-of-range values, and logical inconsistencies. Validation is what transforms extraction into trustworthy output, and it's the layer most frequently skipped in immature architectures.
7. Provenance and Audit Trail
Every transformation, extraction decision, and validation check is logged with a traceable record linking the output back to the source document, the process that produced it, and the timestamp at which it occurred. This audit trail is not optional in insurance. It is a compliance requirement and a legal risk management tool.
8. Structured Output and Downstream Handoff
Validated, structured, traceable outputs are delivered to downstream systems: IDP platforms, LLMs, RAG pipelines, core insurance systems (policy admin, claims management, billing), ECM and RIM platforms, and analytics tools. The handoff should be clean, schema-consistent, and system-agnostic.
9. Exception Management
Documents or data points that fail validation, or that fall below confidence thresholds, are routed to human review queues with context. In a well-designed architecture, exceptions are the minority, not the rule. The goal is focused human review of genuinely ambiguous cases, not manual rescue of broken automation.
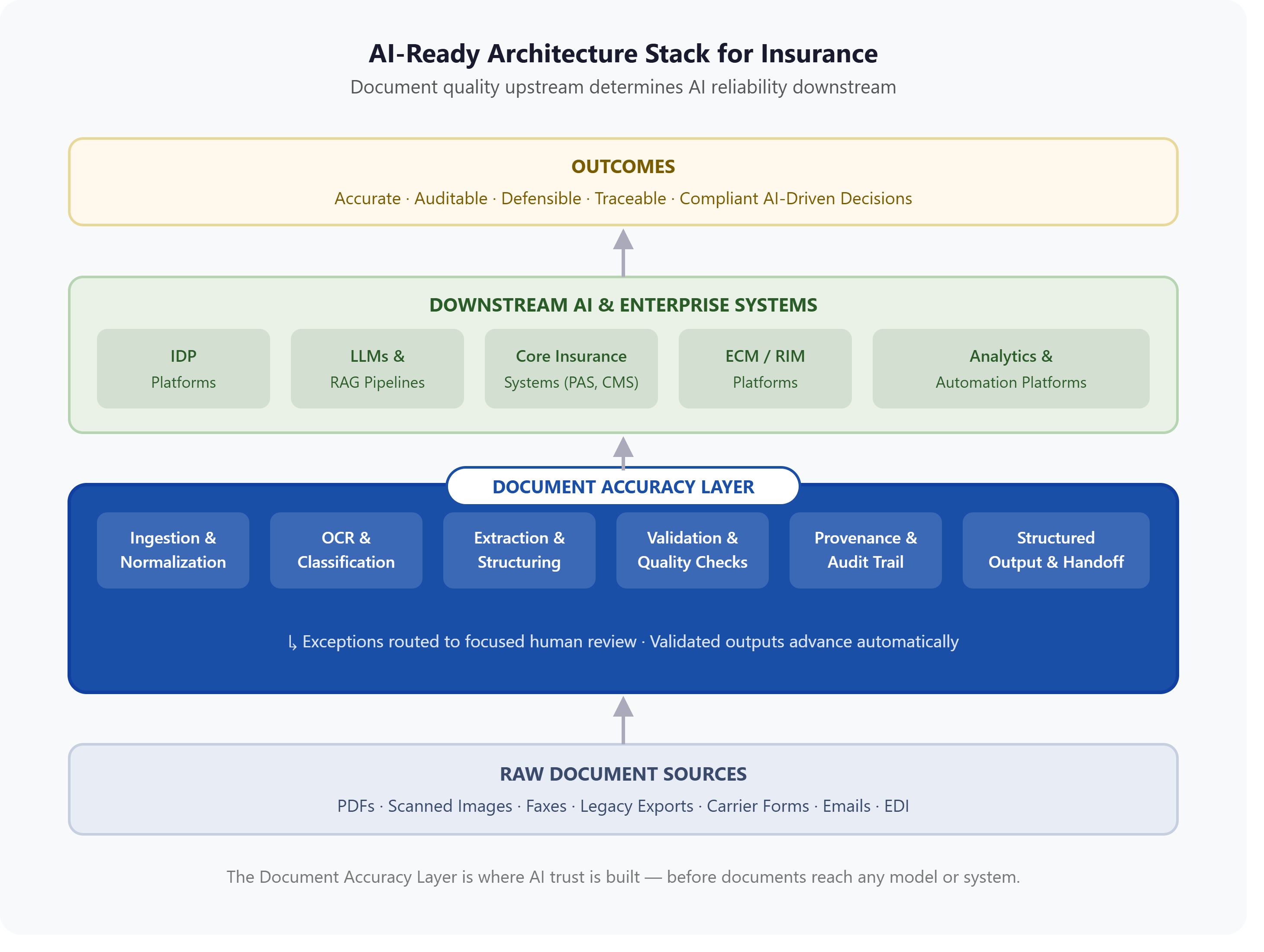
The Document Accuracy Layer: Where AI Trust Is Built in Insurance
The Document Accuracy Layer is the trust and quality foundation positioned between raw document ingestion and downstream AI, automation, and core systems. It is not a single tool, it is an architectural pattern that ensures every document-derived input feeding an AI system has been validated, structured, and made traceable before it reaches the model.
In insurance, the Document Accuracy Layer addresses the most common root cause of AI project failure: not the AI model itself, but the quality, structure, and traceability of the documents it depends on.
Without a Document Accuracy Layer, insurance enterprises typically experience:
- High exception rates in IDP and automation workflows due to poor OCR or misclassification
- LLM hallucinations or fabrications driven by missing, ambiguous, or corrupt source content
- RAG pipelines that retrieve incorrect or incomplete document chunks because source documents weren't properly chunked, structured, or validated
- Compliance exposure when AI-assisted decisions can't be traced back to source documents
- Ongoing dependence on manual review as a permanent cost rather than a targeted exception process
With a Document Accuracy Layer, the inputs to every downstream AI system are clean, structured, validated, and traceable, and the outcomes those systems produce are more accurate, more defensible, and less expensive to operate.
Glossary of Key Terms for AI-Ready Architecture in Insurance
AI-Ready Document
Definition: A document that has been processed, validated, and structured in a way that makes it suitable as an input to AI systems, including LLMs, IDP platforms, RAG pipelines, and automation workflows.
Why it matters in insurance: Most insurance documents in their raw form are not AI-ready. They are scanned images, legacy PDFs, multi-carrier forms, or handwritten submissions. Making them AI-ready requires ingestion, OCR, normalization, extraction, and validation, not just storage or retrieval.
Document Accuracy Layer
Definition: An architectural layer that sits between raw document ingestion and downstream AI, automation, and enterprise systems. It validates, normalizes, structures, and traces document content before it is consumed by any downstream process.
Why it matters in insurance: Insurance AI outcomes, like underwriting decisions, claims payments, reserve calculations, fraud scores, are only as trustworthy as the documents that feed them. The Document Accuracy Layer is where that trust is established.
Unstructured Data
Definition: Information contained in documents, images, emails, or other sources that does not conform to a predefined data model. Unstructured data cannot be directly consumed by most enterprise systems without transformation.
Why it matters in insurance: Industry estimates suggest the vast majority of insurance data is unstructured (i.e., locked in documents rather than structured databases). The inability to reliably extract and structure this data is the primary bottleneck to AI-driven automation in insurance.
Intelligent Document Processing (IDP)
Definition: A category of AI-powered technology that automates the ingestion, classification, extraction, and validation of document content. IDP platforms typically combine OCR, natural language processing (NLP), and machine learning to process documents at scale.
Why it matters in insurance: IDP is a primary automation investment for insurance carriers, TPAs, and MGAs, usually applied to claims intake, policy issuance, accounts payable, and compliance reporting. IDP performance is directly dependent on document quality at input. An IDP system processing poorly OCR'd or unvalidated documents will produce unreliable output regardless of the quality of its underlying models.
Retrieval-Augmented Generation (RAG)
Definition: An AI architecture pattern in which a large language model (LLM) is augmented with a retrieval system that fetches relevant document content at inference time, grounding the model's responses in specific source documents rather than relying solely on training data.
Why it matters in insurance: RAG is increasingly used in insurance for policy Q&A, claims summarization, coverage analysis, and regulatory research. Its accuracy depends entirely on the quality of the document corpus it retrieves from. Documents that are poorly structured, incorrectly OCR'd, or stored without proper chunking and metadata produce unreliable RAG responses, including hallucinations that cite real documents but misrepresent their content.
Straight-Through Processing (STP)
Definition: An automated workflow in which a transaction or document is processed from receipt to completion without manual intervention.
Why it matters in insurance: STP is a core efficiency goal for claims processing, policy endorsements, and premium invoicing. Achieving high STP rates requires that incoming documents be accurate, complete, and structured enough for automated validation rules to pass without human review. Document quality is the primary determinant of STP rates, not the sophistication of the automation platform.
Document Provenance
Definition: The documented history of a document's origin, transformations, extractions, and decisions, establishing a traceable chain from source to output.
Why it matters in insurance: When an AI-assisted underwriting decision is challenged, or a claims payment is questioned in litigation, or a regulator requests evidence of how a document was handled, provenance is what makes the outcome defensible. Without it, the organization cannot demonstrate that its AI-assisted decisions were based on accurate, unaltered source content.
Traceability
Definition: The ability to link any data point, AI output, or automated decision back to the specific source document and the process steps that produced it.
Why it matters in insurance: Traceability is a regulatory and legal requirement in many insurance contexts, particularly for claims handling, policy issuance, and financial reporting. AI architectures that cannot produce traceable outputs create compliance exposure at scale.
Machine-Navigable Content
Definition: Document content that is structured and formatted in a way that software systems, including AI models, can reliably parse, traverse, and extract information from.
Why it matters in insurance: A document that is human-readable is not automatically machine-navigable. A scanned PDF of a loss run may be perfectly legible to an adjuster and completely opaque to an IDP system. Machine-navigability requires deliberate structural work, proper OCR, layout analysis, semantic tagging, and output formatting.
Audit-Ready Output
Definition: AI or automation output that is accompanied by sufficient documentation, such as source references, process logs, confidence scores, validation results, to satisfy audit, compliance, or legal review requirements.
Why it matters in insurance: Insurance operations are subject to regulatory examination, litigation discovery, and internal audit. AI systems that produce outputs without audit trails create legal and compliance risk. Audit-ready outputs allow organizations to demonstrate the accuracy, integrity, and traceability of their automated processes.
Validation Layer
Definition: A processing stage in which extracted or transformed data is checked against defined rules, schemas, reference data, and business logic before being passed to downstream systems.
Why it matters in insurance: Validation is the mechanism by which document errors, OCR mistakes, and extraction anomalies are caught before they enter core systems. A robust validation layer reduces exception rates, improves STP rates, and prevents compounding errors in downstream AI models that treat flawed inputs as ground truth.
Exception Handling
Definition: The process of routing documents or data points that fail automated processing, due to low confidence, validation failure, or missing fields, to a human review queue for resolution.
Why it matters in insurance: Exception handling is unavoidable in any document-intensive workflow. The goal of AI-ready architecture is not to eliminate exceptions entirely but to reduce them to a manageable, targeted set of genuinely ambiguous cases, rather than routing a large percentage of volume to manual review because the automation is failing on basic quality issues.
Large Language Model (LLM)
Definition: A type of AI model trained on large text corpora that can understand and generate natural language. LLMs are used in insurance for summarization, Q&A, document analysis, correspondence generation, and decision support.
Why it matters in insurance: LLMs are increasingly embedded in insurance workflows, but they do not have inherent quality filters on their inputs. An LLM that receives a garbled, incomplete, or structurally inconsistent document will generate responses based on that flawed input, often with high apparent confidence. Document accuracy upstream is the primary safeguard against LLM errors in regulated insurance workflows.
OCR (Optical Character Recognition)
Definition: Technology that converts image-based text, like scanned documents, photographs of forms, faxes, into machine-readable text.
Why it matters in insurance: OCR is the foundational step for making scanned insurance documents processable. OCR accuracy varies significantly based on document quality, scan resolution, font variation, handwriting, and form complexity. OCR errors that are not caught and corrected in a validation layer propagate through every subsequent processing step and can produce extraction failures, misclassifications, and incorrect AI outputs.
Document Fidelity
Definition: The degree to which a processed or converted document accurately preserves the content, structure, layout, and meaning of the original source.
Why it matters in insurance: In insurance, documents serve as legal instruments. A certificate of insurance, a policy declaration, or a signed claims form may be required to match its original exactly, including tables, signatures, annotations, and formatting. Fidelity loss during processing can invalidate documents as legal evidence and create compliance exposure.
Model-Agnostic Architecture
Definition: An architectural approach in which the document processing and accuracy layer is designed to work with any AI model, IDP platform, or downstream system, rather than being locked to a single vendor's stack.
Why it matters in insurance: Insurance IT environments are complex and heterogeneous. Carriers, TPAs, and MGAs operate multiple core systems, analytics platforms, and AI tools from different vendors. A model-agnostic Document Accuracy Layer improves documents once, and then delivers clean, structured outputs to every downstream system simultaneously, without requiring system-specific customization.
6 Common Failure Modes in Insurance AI Architecture
Understanding why insurance AI projects underperform is as important as knowing what good architecture looks like. These are the most common root causes.
1. Feeding AI systems with unvalidated source documents.
Organizations connect IDP or LLM tools directly to raw document repositories (email inboxes, legacy ECM systems, scanned file shares) without any normalization or validation layer. The models process whatever they receive, including corrupt scans, incomplete submissions, and legacy formats that predate current standards.
2. Treating OCR as sufficient for AI readiness.
OCR converts images to text, but it does not validate accuracy, correct errors, structure the output, or produce traceable results. An OCR pass that produces 95% character accuracy on a 500-field loss run still produces potentially dozens of errors that can cascade through downstream automation. OCR is a necessary first step, not a complete solution.
3. No traceability between AI output and source document.
hen an AI-assisted decision is questioned by a claimant, a regulator, or an internal auditor, the organization must be able to trace that decision back to the source document that informed it. Architectures that don't log this provenance cannot respond to challenges, creating compounding legal and compliance risk.
4. Exception queues that grow instead of shrink.
Organizations assume that deploying automation will reduce manual review workload. When the underlying documents are not AI-ready, automation fails on a large percentage of submissions, and the exception queue becomes larger than the manual process it was intended to replace. Exception volume is a direct measure of document quality, not automation capability.
5. Assuming prompt engineering fixes document quality problems.
Prompting an LLM more carefully does not compensate for a source document that is missing data, incorrectly OCR'd, or structurally inconsistent. Better prompts improve the model's use of good inputs, they cannot create good inputs from bad ones. Document accuracy is an upstream infrastructure problem, not a model configuration problem.
6. Deferring document quality to the post-automation cleanup phase.
Organizations plan to "fix quality issues as they arise" in production. In practice, document quality problems at scale produce a volume of exceptions that cannot be addressed retrospectively without significant cost. Quality gates belong upstream, before documents reach AI systems, not after.
What Good Looks Like: Evaluating AI Document Readiness in Insurance
Before scaling AI in any insurance workflow, operations and technology leaders should be able to answer these questions:
Can every AI-assisted output be traced back to a specific source document? If not, the architecture lacks the provenance layer required for audit and regulatory defense.
What percentage of document submissions are being routed to manual review, and why? High exception rates indicate that the document accuracy layer is absent or underperforming, not that automation isn't advanced enough.
Are all document formats that actually arrive in this workflow supported, including legacy formats, handwritten forms, and multi-carrier submissions? Architectures designed around clean, digital-native documents will fail on the full diversity of real insurance document intake.
Is extracted data validated against business rules before it enters downstream systems? Extraction without validation produces outputs that look structured but contain errors that core systems, AI models, and analysts will act on as ground truth.
Does the architecture support model and platform interoperability? A document accuracy layer that is locked to a single AI vendor creates downstream dependency risk as the AI landscape evolves.
Are documents treated as evidence, with fidelity, provenance, and immutability requirements, or simply as data containers? In insurance, documents are legal instruments. The architecture should reflect that.
Can the organization demonstrate to a regulator or in litigation exactly how a specific document was processed, what was extracted, and what decisions it informed? If the answer is no, the architecture is not audit-ready at scale.
How Adlib Addresses AI-Ready Architecture for Insurance
Adlib operates as the Document Accuracy Layer for insurance enterprises scaling AI, automation, and digital transformation. Adlib ingests multi-format insurance documents, including PDFs, scanned images, legacy system exports, and carrier-specific forms, and produces validated, structured, traceable outputs that downstream AI systems, IDP platforms, and core insurance systems can reliably consume.
Adlib's platform is model-agnostic and interoperable by design: it improves document quality once and delivers clean outputs to every downstream system simultaneously, without requiring rip-and-replace of existing infrastructure.
The result is AI inputs that are more accurate, more auditable, and more defensible, and AI outcomes that insurance operations, compliance teams, and regulators can trust.
FAQ
What is AI-ready architecture for insurance?
AI-ready architecture for insurance is the set of technical components and processing layers that prepare insurance documents and data for reliable, accurate, and auditable use by AI systems. It includes document ingestion, normalization, OCR, classification, extraction, validation, and provenance tracking, establishing a trust layer between raw source documents and downstream AI models, IDP platforms, and automation workflows.
Why do insurance AI projects fail?
Insurance AI projects most commonly fail or underperform, not because of problems with the AI models themselves, but because of the quality and structure of the documents being fed into those models. Unvalidated, inconsistently formatted, or untraceable documents produce unreliable AI outputs regardless of model sophistication. Document accuracy upstream is the primary determinant of AI reliability downstream.
What is a Document Accuracy Layer?
A Document Accuracy Layer is an architectural layer that sits between raw document ingestion and downstream AI, automation, and enterprise systems. It validates, normalizes, structures, and traces document content before any downstream system consumes it. In insurance, the Document Accuracy Layer is the mechanism by which organizations ensure that the documents feeding their AI systems are accurate, complete, and defensible.
What makes a document AI-ready in insurance?
A document is AI-ready when it has been processed through OCR (if image-based), normalized into a consistent structure, had its key data fields extracted and validated, been linked to a provenance record, and produced a clean, machine-navigable output suitable for consumption by downstream systems. Most raw insurance documents (scanned PDFs, carrier-specific forms, legacy exports) are not AI-ready without deliberate processing.
How does document quality affect AI accuracy in insurance claims processing?
In claims processing, AI systems depend on accurate extraction of claimant data, loss amounts, reserve figures, coverage details, and supporting documentation. When source documents contain OCR errors, missing fields, or structural inconsistencies, extraction tools produce errors that propagate into claims decisions, resulting in incorrect payments, delayed settlements, and compliance exposure. Document quality upstream directly determines AI accuracy in claims outcomes.
What is the difference between IDP and a Document Accuracy Layer?
IDP (Intelligent Document Processing) is a technology category focused on automating document classification, extraction, and routing. A Document Accuracy Layer is an architectural concept, a processing stage that validates, structures, and traces documents before they reach IDP or any other downstream system. In a well-designed architecture, the Document Accuracy Layer improves the inputs that IDP systems receive, increasing IDP accuracy and reducing exception rates.
How does RAG perform with unstructured insurance documents?
RAG (Retrieval-Augmented Generation) performance depends on the quality of the document corpus it retrieves from. When insurance documents are stored without proper OCR, chunking, metadata, or validation, RAG retrieval returns incorrect, incomplete, or ambiguous content, and the LLM generates responses based on that flawed context. This can produce plausible-sounding but factually incorrect answers to coverage questions, claims summaries, or policy analyses. AI-ready document preparation is a prerequisite for reliable RAG in insurance.
What compliance requirements apply to AI document processing in insurance?
Requirements vary by jurisdiction and line of business, and organizations should verify specific requirements with legal and compliance counsel. Generally, insurance regulators expect that AI-assisted decisions in underwriting, claims, and pricing, be explainable, auditable, and traceable to source data. Architectures that cannot demonstrate a clear chain from source document to AI output create regulatory exposure.
Why isn't better prompting enough to fix document quality problems in insurance AI?
Prompt engineering improves how an AI model uses its inputs, it cannot improve the quality of those inputs. If a source document is missing data, contains OCR errors, or is structurally inconsistent, a more carefully worded prompt will not recover that information. Document accuracy is an infrastructure problem that must be solved upstream, before documents reach AI models. Treating it as a prompt optimization problem produces diminishing returns and persistent quality failure.