

Share Post
This post is the first in a four-part weekly series on document transformation for leaders striving to better access and leverage enterprise-wide content.
Business leaders worldwide are struggling to transform into agile, compliant, and competitive digital entities. What stands in their way is a consistent and reliable flow of documents and data—any company’s most valuable assets—which are needed to accelerate customer experiences, inform decisions, mitigate risk, and meet compliance regulations with agility.
According to Gartner, leaders who share data externally generate three times more measurable economic benefit than enterprises that do not.
The primary challenge in creating a unified flow of high-value information is that it is typically scattered across departments and in disparate systems and repositories. Content arriving via email or the web, legacy data stored in repositories, and net-new data created daily across an organization create a complex challenge and opportunity. The mountains of unstructured data, often in hundreds of different file types, makes document process automation even more complicated. Moreover, companies are increasingly burdened with ever-growing volumes and varieties of content. As a result, businesses are expending significant resources combing through large volumes of content manually, an inefficient process rife with errors and risk that ends up hampering downstream initiatives.
Consistent and complete access to content enhances internal workflows and facilitates external collaboration.
The first phase of the content lifecycle across industries is capturing data. Adlib’s document transformation platform automatically locates and prepares data across file types and systems at scale, from new policy and supplier onboarding to customer claims approval to financial document standardization.
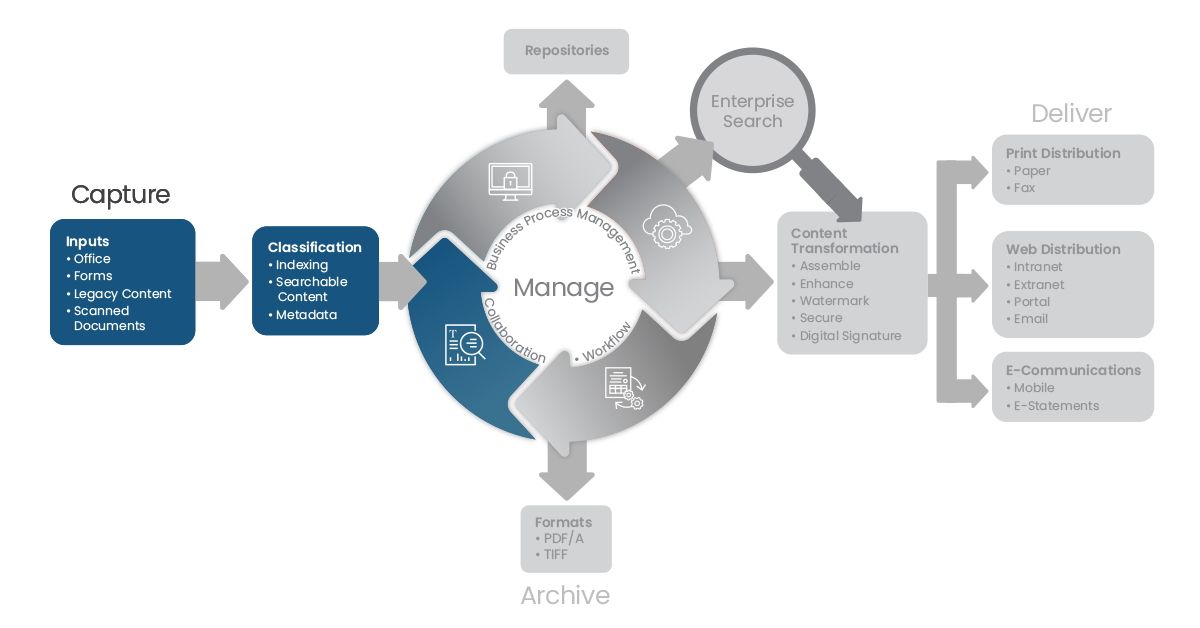
Content Lifecycle - Capture
Capture Inputs From Sources.
Manual efforts to discover data across an enterprise regardless of location or format, including MS office, images, emails, and even CAD files, are virtually impossible primarily due to the increasing content volume and the various applications required to open them. Yet, many businesses still rely on manual processes to manage their legacy and net-new data.
For instance, banks are grappling with massive amounts of incoming content related to customer onboarding, opening accounts, mortgage lending, and fraud detection. Similarly, insurance companies manage reams of customer information, including onboarding documents, policy claims, and billing correspondences. In these industries, capturing data from various inputs are required to accelerate workflows and create more robust customer experiences.
The Burden of CAD Drawings
In the manufacturing and oil and gas sectors, distributing CAD schematics is vital to ensuring smooth operations, meeting compliance requirements, and mitigating risk. CAD drawings can exist in repositories, web portals, emails, or other sources and are often large and complex. Normalizing different CAD formats to high-quality PDF speeds up internal workflows and facilitates external collaboration. For instance, after automatically converting all suppliers’ CAD documentation to PDF, they can be quickly shared with oil and gas engineers in the field to do pump inspections and repairs on the spot. Manually capturing CAD drawings generates errors and makes troubleshooting less effective.
Without reliable access to all relevant CAD data, companies waste valuable resources identifying and converting these files to meet compliance checks, support engineers in the field, and bring products to market.
Benefits of Automated Data Capture:
- Enhances customer experiences
- Ensures greater operational efficiency
- Reduces risk and shores up compliance
Classification:
Once the correct data has been captured, it needs to be organized. It is easier to surface valuable data when documents are grouped by type, indexed, and metadata-tagged. Automated classification enables teams to extract relevant content faster, at scale, and with fewer errors than any manual process. Highly searchable data is available to downstream entities who depend on certain information to execute their jobs at the highest level.
When organizations have a universal metadata structure, disparate systems can automatically connect and make critical data available faster.
Adlib’s document transformation solution automatically assigns appropriate document classification and metadata mark-ups to automate processes, mitigate risk, and prioritize innovation.
The Final Verdict
If you are among the many corporate leaders juggling heaps of data only to watch much of it fall by the wayside, you are not alone. Enterprises that automatically identify, extract, and classify information flooding in are taking an important first step toward transforming their data into stronger, more actionable insights. Adlib’s document transformation platform puts forward-thinking executives in control of their most valuable asset to thrive and innovate in today’s hypercompetitive global economy.
Check out next week’s post on how to manage content to improve business process automation dramatically.

